Abstract
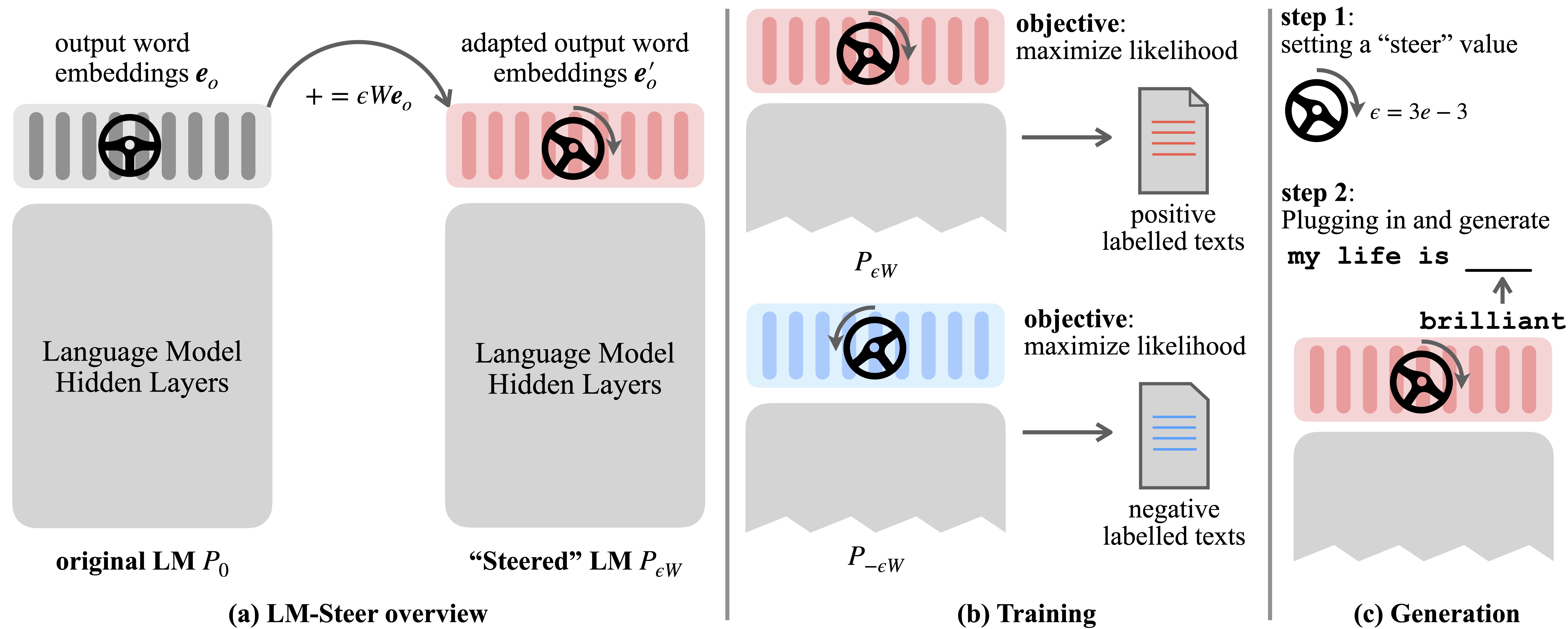
Language models (LMs) automatically learn word embeddings during pre-training on language corpora. Although word embeddings are usually interpreted as feature vectors for individual words, their roles in language model generation remain underexplored. In this work, we theoretically and empirically revisit output word embeddings and find that their linear transformations are equivalent to steering language model generation styles.
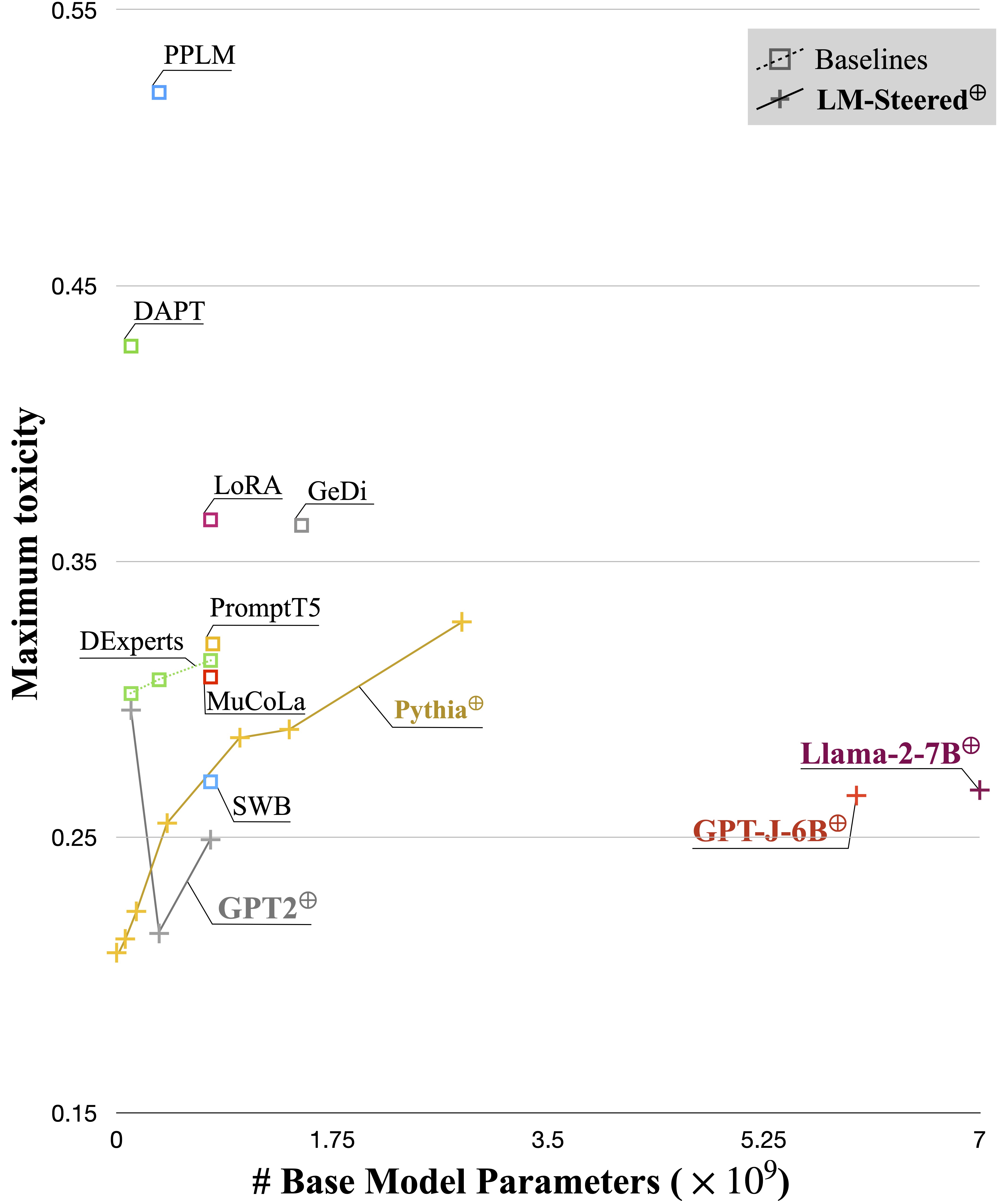
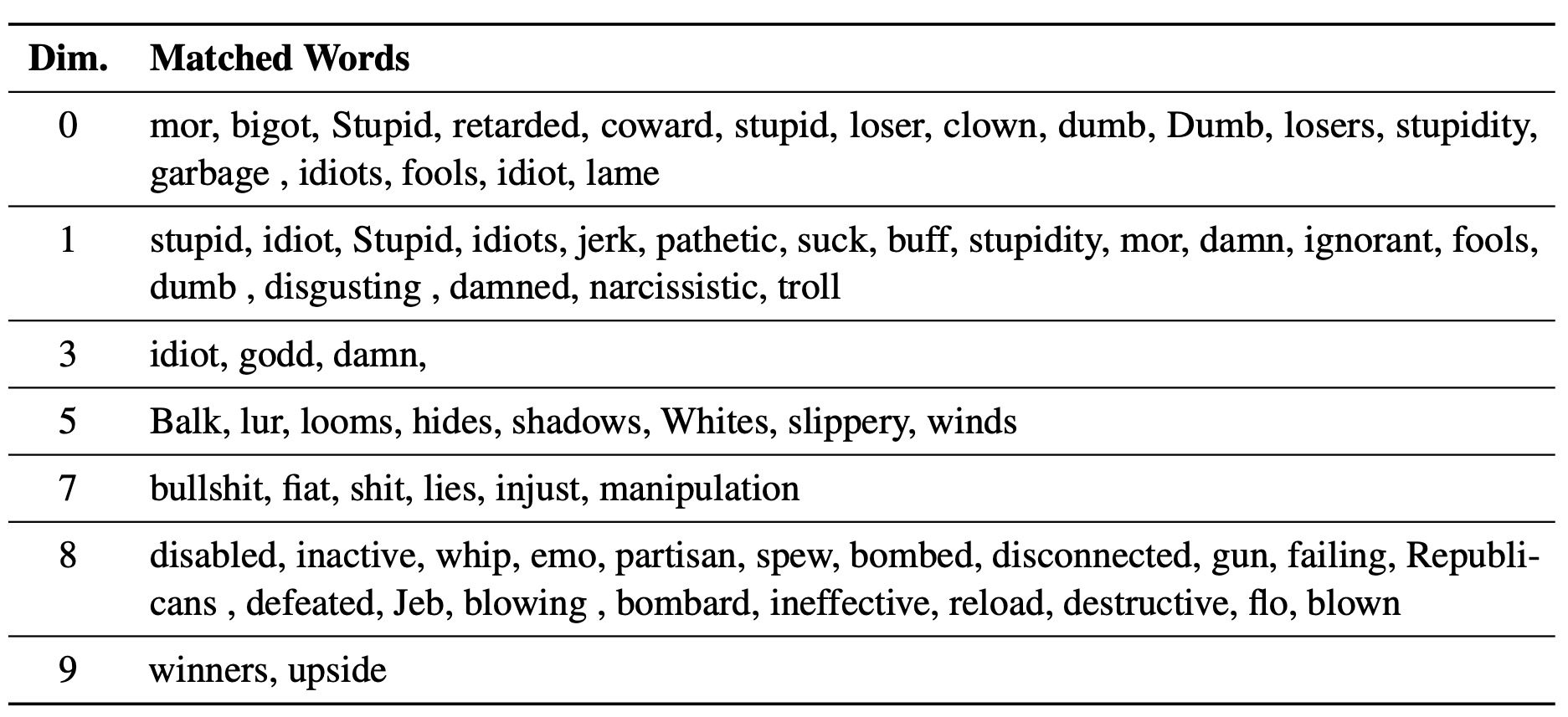
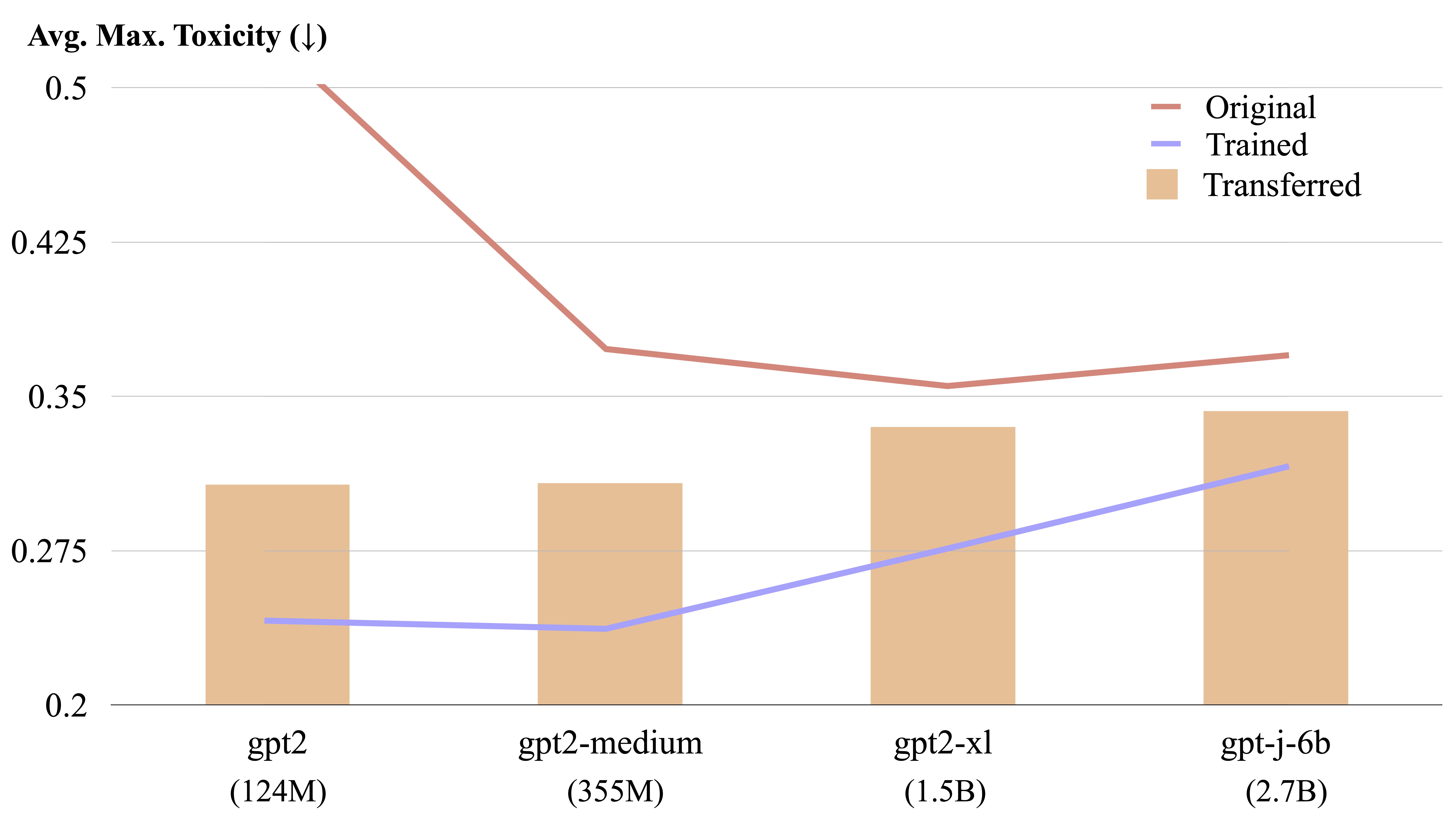
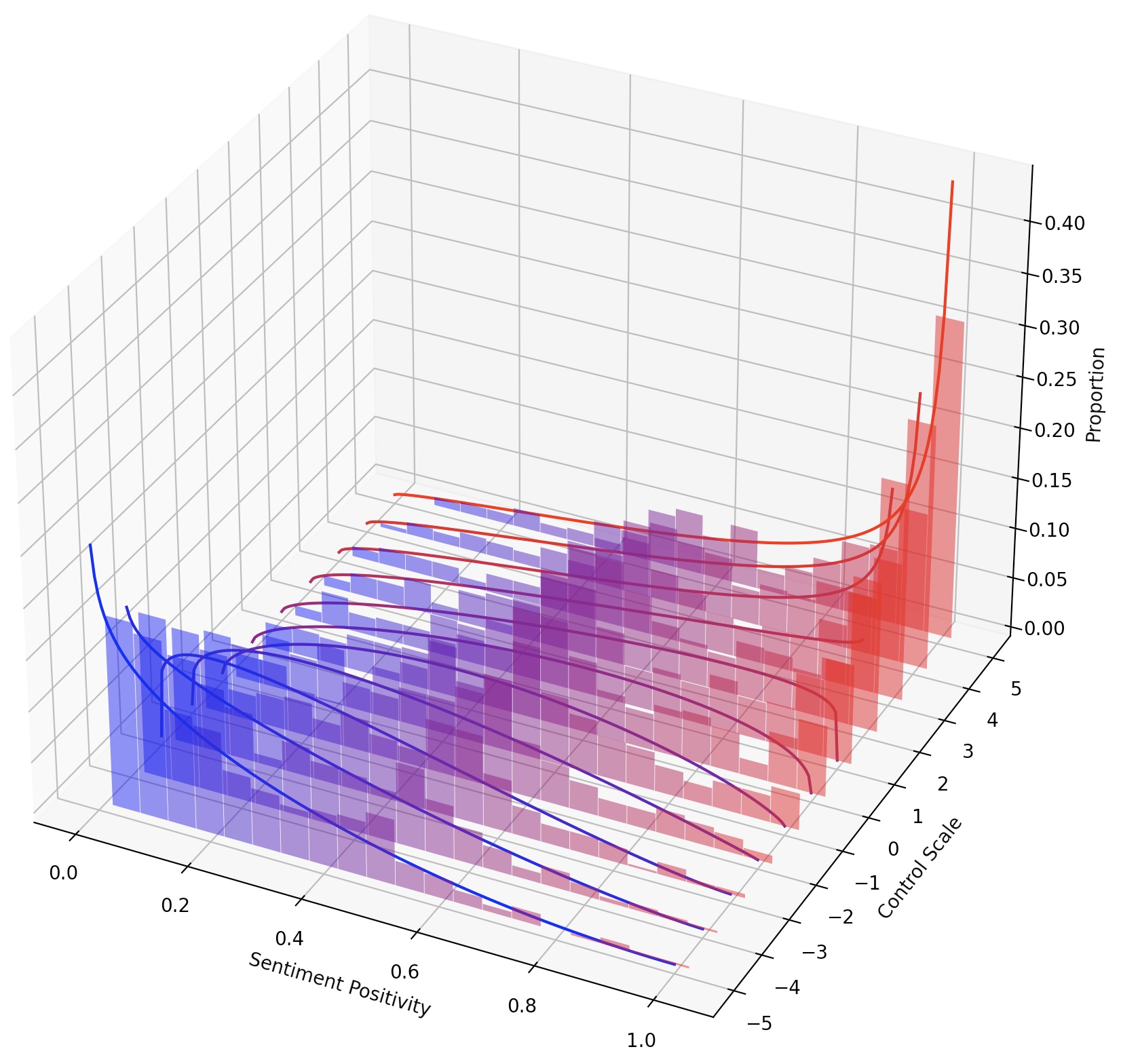
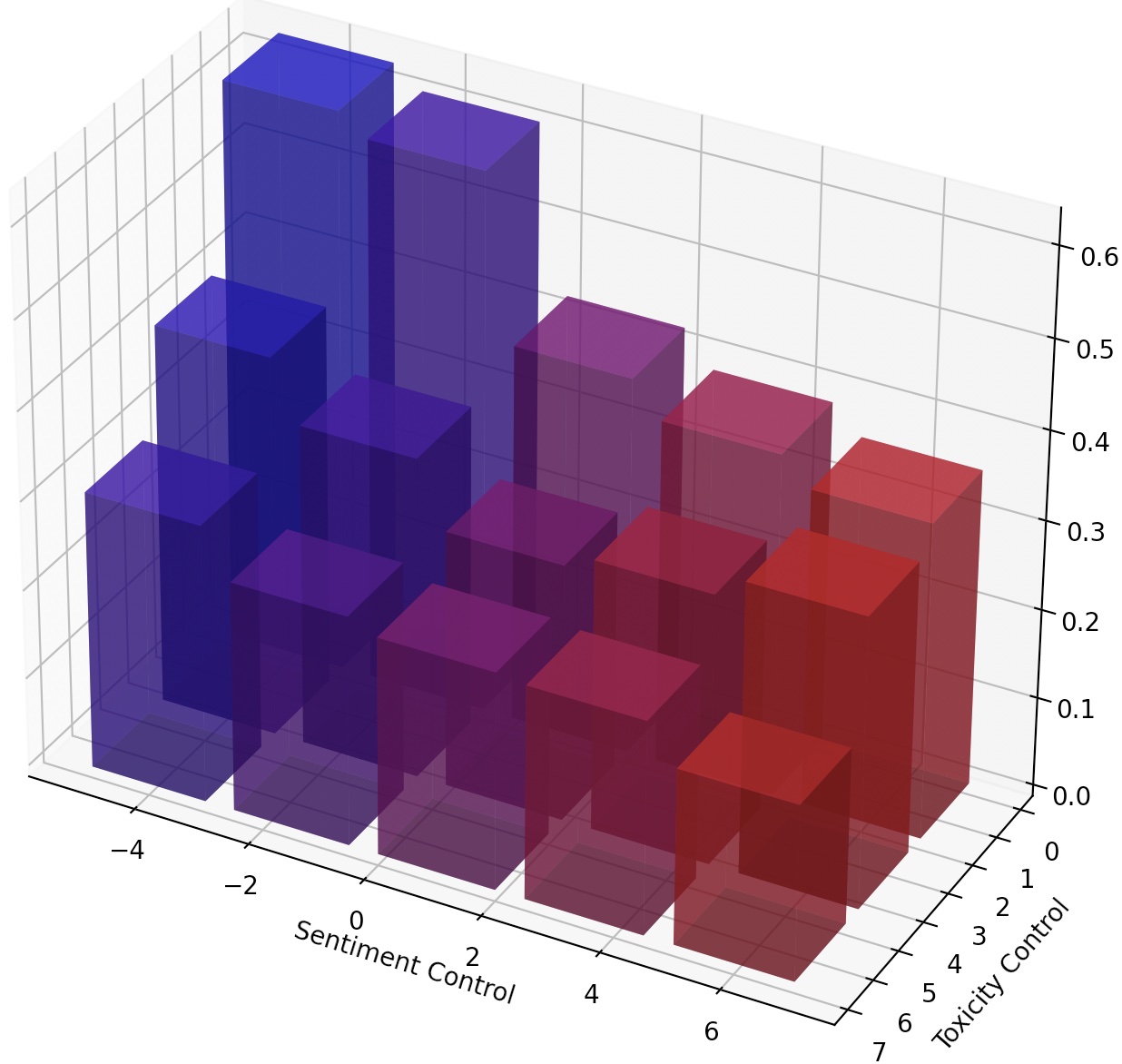
We name such steers LM-Steers and find them existing in LMs of all sizes. It requires learning parameters equal to 0.2% of the original LMs' size for steering each style. On tasks such as language model detoxification and sentiment control, LM-Steers can achieve comparable or superior performance compared with state-of-the-art controlled generation methods while maintaining a better balance with generation quality.